
|
This article originally appeared in Geospatial Solutions Magazine's Net Results column of April 1, 2003. Other Net Results articles about the role of emerging technologies in the exchange of spatial information are also online. |
| 1. Introduction and Glossary 2. How's my complexion? 3. Updating that little black book 4. Delayed gratification | |
| Delayed gratification. Another approach
allows updates to the same data by many sites, known as bidirectional replication,
but dilutes atomicity. Bidirectional replication software propagates updates
throughout the distributed system after the original transaction commits locally.
This delayed propagation approach is clearest in the context of the typical
delayed propagation demonstration environment — two networked laptops with
identical map displays. First the presenter updates laptop A by subdividing an
assessor’s parcel. Like magic, the same parcel subdivides on laptop B. Then the
presenter disconnects the network cable and subdivides another parcel on laptop
A. Of course, nothing happens on laptop B. Then, when the presenter reconnects
the network, shazam!, the parcel subdivides. The change waits in a queue on laptop
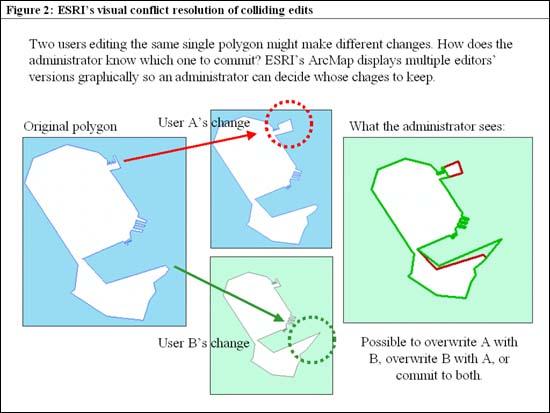
A until it either successfully reaches all its remote targets or times out. Less often, before reconnecting the network cable, the presenter updates the same parcel differently on both laptops, A and B. Then, at reconnection time, each laptop tries to update the other, and (hopefully) discovers a conflict. Software supporting nonspatial data replication allows DBAs to decide in advance how to resolve conflicts. Some organizations decide to compare timestamps for each change and favor earlier or later changes. Others designate a primary editor whose changes always overwrite those of other editors. Or, a senior administrator may review all conflicts and make the choice case by case. Between uni- and bidirectional replication strategies is a hybrid approach that keeps data close to its owners based on either geographic regions or, more commonly, departmental responsibility. For instance, the fire department may be the sole editors of fire hydrants, and public works may own and exclusively edit street centerlines, but both can see each others’ data and changes thanks to replication (figure 1). Spatial data replication conflict resolution can use timestamps or primacy, also, but can’t be decided manually without graphic maps. Users of ESRI’s (www.esri.com) geodatabase are familiar with the multiversioned editing model whereby conflicts appear on a map, color-coded by owner. The administrator evaluates conflicts graphically before commiting to one or the other (or both) changes (figure 2). Within the framework of ESRI’s versioned geodatabase model, this solution works well. For the time being, however, replication software such as OmniReplicator and spatial data editing software such as ArcGIS do not yet collaborate seamlessly. As Date observed 10 years ago, when replication of standard data types was in its infancy, the main disadvantage of distributed systems was their complexity. Unifying software solutions across multiple databases, GIS, and replication software products face the same challenging path. Though within reach, the productized solutions for spatial data replication across multiple databases, hardware, operating systems, and networks is still an emerging rather than a mature technology. |
|
|
The end of the beginning Replication of spatial data in a distributed database system is an enormous and (in my opinion) fascinating subject. Beyond the scope of this simple summary are architectural details worthy of their own columns. For instance, how each distinct database connects to the rest of the enterprise, known as network topology, directly influences update propagation speed. Distributed database architects concerned about performance must consider the mechanism for alerting the replication software to changes in the database, usually either trigger-based or log-based. Even the seemingly simple root-controlled primary copy strategy can be hybridized to use multiple data-specific primary copies, such as an electricity provider’s system in which finance is the root editor of the replicated finance database and engineering is the root editor of utilities data. Hopefully an appreciation for the complexity of replication across a distributed enterprise helps explain why the spatial industry is proceding slowly and cautiously to extend the replication work already done by database vendors and system architects. We stand on the shoulders of giants.
|
| 1. Introduction and Glossary 2. How's my complexion? 3. Updating that little black book 4. Delayed gratification |
|
|