
|
This article originally appeared in Geospatial Solutions Magazine's Net Results column of April 1, 2003. Other Net Results articles about the role of emerging technologies in the exchange of spatial information are also online. |
| 1. Introduction and Glossary 2. How's my complexion? 3. Updating that little black book 4. Delayed gratification | |
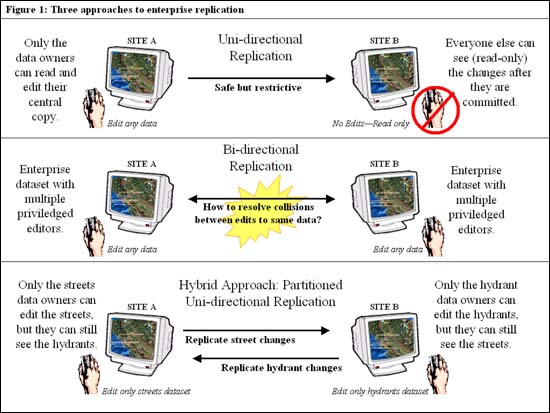
| Updating that little black book Within a single database, the overhead of data protection mechanisms such as atomicity and locking may be so small as to be irrelevant; local disk access rates easily outperform wide area network transmission speeds. But a distributed database system relies on the network as an integral part of the overall virtual data collection. And the network is slow. Imagine the wait if, before allowing you to edit a street, the system had to check all other networked databases for pre-existing locks on the enterprise’s street table. Multi-site coordination adds overhead and hurts performance just as multiuser coordination in a single database does, but with a higher performance cost. Consequently, architects of distributed systems try to minimize their use of the network, sending as few and as brief messages as possible to keep the enterprise data clean and available. Commitment phobia. A key strategy for minimizing network utilization is data replication--the automated storage and maintenance of data copies at different distinct sites. With replicas of the enterprise’s data deployed at many distinct sites, applications can operate on local copies of the data instead of having to communicate with remote sites. The replication software keeps all sites up to date by broadcasting changes throughout the system. If you followed the earlier summary of data protection, you’ll realize the basic problem with data replication: to guarantee atomicity and concurrency across the enterprise, no transaction should be allowed to commit until it has completed successfully not just in the local database, but also on all replicates in the distributed system. The problem is that if even one site is unavailable for any reason, no other site will be able to update anything! Similar to decision making by absolute consensus, the downed site can’t copy the local update, so it can’t send back a commit confirmation. Without confirmation, attempted transactions must roll back. Organizations and vendors work around this problem in several ways. One is to accept a less ambitious definition of distributed database systems. Instead of allowing every site to update the enterprise dataset, one site becomes the "root" responsible for the primary copy. Root changes to the primary copy ripple out to secondary, read-only copies at remote sites. This strategy allows both the primary and any disconnected sites to operate continuously (with outdated data at the remote site), until a restored connection brings them back into synch with the primary dataset. |
|
|
This unidirectional replication (figure 1) works well for distributed
organizations whose satellite offices collect their own local data, and the
headquarters summarizes and reports on the total collection. At the California
Water Resources Board (www.swrcb.ca.gov), for instance, many remote offices
collect streamflow data from field sensors and load the data into local IBM
Informix (www.ibm.com) spatial databases, which then replicate the data to a
read-only warehouse at headquarters. The resulting reports integrate the
streamflow for all sensors.
|
| 1. Introduction and Glossary 2. How's my complexion? 3. Updating that little black book 4. Delayed gratification |
|
|